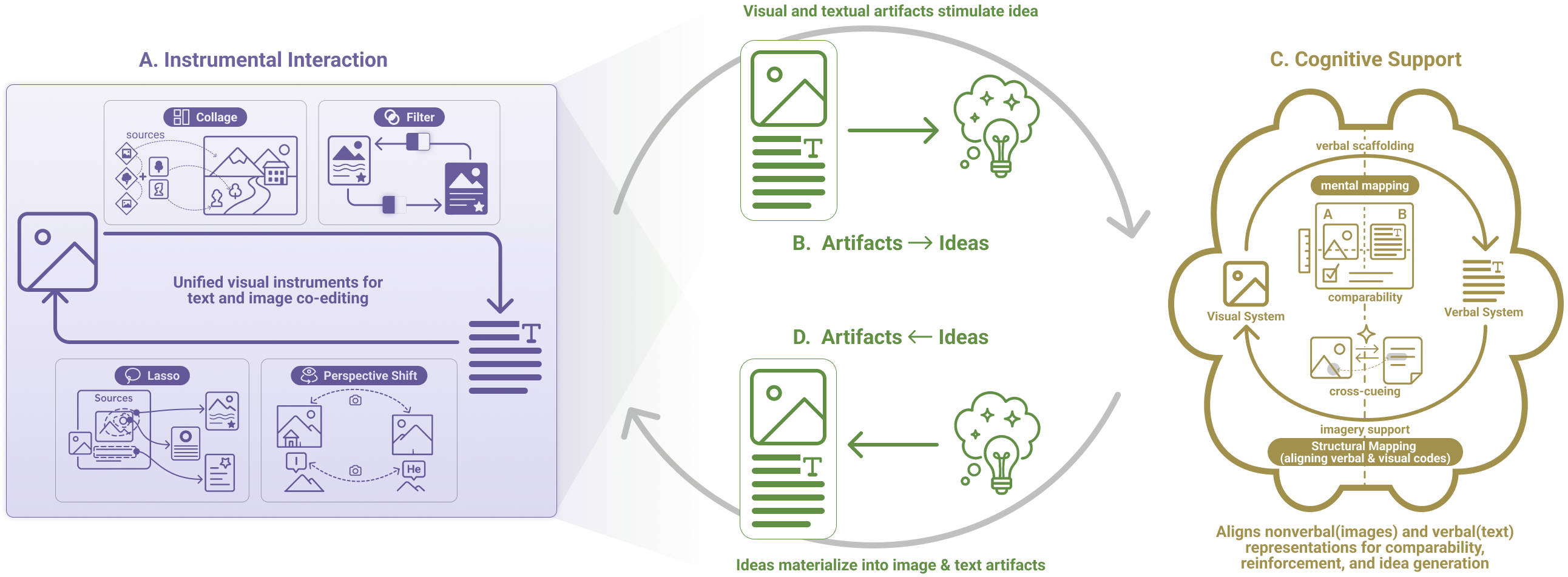
Human thinking involves multimodal processing. Visual processes play a central role in cognition: we recall experiences as spatial scenes, form mental models through imagery, and use visual structure to organize and interpret information. Language is similarly entwined with imagery. Text comprehension often evokes mental pictures, and abstract ideas are commonly articulated through spatial metaphors such as path, framework, or perspective.
Story writing is particularly multimodal in nature. During the planning phase, experienced writers often use both imagery and language to construct the story world. They visualize spatial layouts, character interactions, and scene dynamics, while using textual notes to label, sequence, and reason about narrative structure. In the translating phase, visual details serve as an anchor that shapes how writers organize narrative detail and emotional tone.
Yet, current writing tools remain overwhelmingly text-centric. Although recent systems powered by Large Language Models incorporate visual elements through image generation or retrieval, these visuals remain peripheral. They function mainly as prompts, static references, or organizational diagrams, rather than as tightly integrated, manipulable representations along with text.